April 3, 2025
Swoncord - Discord Rich Presence from Swinsian
I use a music player called Swinsian. You can think if Swinsian as if Apple never invented the iPod and didn’t make iTunes into a laggy mess many years ago, it’s a focused music player driven by a SQLite database that’s lightweight, fast and rock solid. The developer is very incognito and development seems to have stalled but beta versions for v3 are discoverable if you know where to look.
Discord has this cool feature called “Rich Presence” which allows third party apps to display a short status of what you are currently doing. It’s a realtime ephemeral feed and the most common thing you’ll see is people listening to music or playing games. A few years ago I toyed around with the idea of displaying Swinsian as a Discord Rich Presence. I took a stab at it then and built something really janky. This approach used AppleScript to query Swinsian, manually formatted that AppleScript into JSON, parsed the JSON in Rust and posted the result to the Discord IPC pipe. It was a CLI tool that I quickly forgot about as it was tedious to turn it on and off and I eventually gave up on it.
Story could have ended there but as happened with the Slow Electric Vol.1 mix, someone randomly reached out to ask me ‘how do I build this thing and make it work’ . Sadly the knowledge gap for this individual was too wide for me to bridge as I didn’t really feel in the mood of educating someone how to use a terminal, but the interaction reminded me that I at one point had this tool. A larger trend in my life lately has been to try to finish projects where I gave up or got distracted, for things I still would want to exist in my life. Separately, we played around with some ideas internally at Discord that surfaced rich presence in a more fun way and at this point it’s clear to me that I should give this thing another shot.
Digging the project up again, I quickly realized what the dead end was. Polling with AppleScript is honestly quite icky but seemed to me to be the only way to get the data. Looking deeper, Swinsian documents some ‘developer’ keys that I could use but this seemed opauqe to me? I gave it a shot and implmented a simple NSDistributedNotificationCenter client in Rust that would listen to all the notification queues and just tell me Swinsian actually posted, not just what they document. Lo and behold the player posts way more data than what’s documented on the webpage, it’s basically firing of the entire data model as an event, which means we have artist, album, title, genre, composer, track_number, disc_number, year, length, current_time, track_uuid, art_path, thumbnail_path, file_path, file_type, bitrate, grouping, conductor & comment.
let block = ConcreteBlock::new(move |notification: id| {
let name: id = msg_send![notification, name];
let name_str = NSString::UTF8String(name);
let name_rust = std::ffi::CStr::from_ptr(name_str).to_string_lossy();
let user_info: id = msg_send![notification, userInfo];
if user_info != nil {
let track_info: TrackInfo = TrackInfo::from(user_info);
sender.send((State::from(name_rust.as_ref()), track_info)).unwrap();
}
});
let block = block.copy();
let _: () = msg_send![self.notifciation_center,
addObserverForName:track_playing
object:nil
queue:nil
singBlock:&*block];
ewwwwwwwwwwwwwwwwwwwwwwwwwwww
Working on this makes me realize how ‘true’ Cocoa & Objective-C tried to be to Smalltalk, it’s all basically message passing between the app and the operating system, where you package upp messages with structs and pointers and fire them of to Objective-C land. It seems reading about it that this is changing with Swift but it’s a very fundamentally different approach from the Win32 style programming. Yes, I’ve read about it 100 times and written Swift but interfacing against Cocoa from Rust strips away all of the syntactic sugar that Objective-C layered on top of this paradigm.
After writing some really jank Objective-C object parsing in Rust and got a stable path for extracting all values I had two more things to solve for: album art and minimal UI. I initially considered just uploading the album art every time I switched song to some serverless function on Cloudflare but ended up querying MusicBrainz, as they already have a good way to serve album art.
For the minimal UI, I really wanted the app to be a MacOS menu bar app. MacOS menu bar app are these small icons on the top of your desktop that either indicate status or serve as entrypoints to single-purpose apps. Initially I tried using tray-item, but MacOS expects there to be only one main thread recieving messages. Once I added this in conjunction with the message handlilng thread, MacOS yanked execution from underneath me. Since I already had the reference counting setup, I took a shot at wrangling more Rust around the NSStatusBar API myself. The hardest part ended up being figuring out the resource mapping between Rust and what an .app bundle expects for icons.
After one evening of wrangling, it’s up on github. It’s such a small nerdy feature but honestly sometimes we all have to take a break and make these features that benefits noone but yourself. It’s even debatable if benefits me LOL.
March 16, 2025
Garmin Varia Seatpost Extender
I’m doing a longer bike ride (200 miles / 320 km) next week in an unsupported fashion. I’m expecting this to take a fair bit of time given I have to go through 6 large cities, so I’m preparing for a long day out. The challenge of this is how to pack, if this was a race (let’s say Vätternrundan), the time to completion would be shorter and there are support stations along the way. To do this unsupported in a day I will have to carry a bit more than 3 gels and a thermal vest, with temperatures ranging from 4C to 23C over the day. My current smaller saddle bag only fits a spare tube, CO2 cartridge and some tools so that’s sadly a non-starter.
Bought a larger saddle bag on a whim after having good experiences with their frame mounted top bag. It arrived great but there was only one problem: it was deep enough that it obscured the Varia and blocked the light. The Garmin Varia RTL515 is a small bike light combined with a 24 GHz radar that wirelessly transmits the distance of cars coming from behind to a Garmin bike computer. I held off on this for a long time but after getting one in 2022 it is one of the few things I rarely ride without. You get a very predictable idea of what’s behind you when on the road.
How does one solve this? I could strap the radar to the saddle bag but I was worried that the less rigid nature of the saddle bag would have the radar bouncing around, thus reducing the predictability of the radar. I looked at some ideas and realized that garmin mount inserts are dirt cheap which would allow me to build my own mount.
The bike I’m planning on riding for this distance is my Specialized Roubaix Expert from 2020. It excels when it comes to comfort over long distances without sacrificing too much efficiency (other than a less aero position). As is becoming more and more common, the bike is using a non-standard seatpost shape, in this case a D-shaped S-Works Pavé SL Carbon Seatpost. It’s therefore a bit tricky to figure out how to make a perfectly shaped clamp for this seatpost in 3D. As I lack a traditional engineering background, I honestly don’t know how to capture angles from something into CAD using tools only, the way I’ve found work is to just slap the thing I am trying to measure on a flatbed scanner and use that as a reference to draw it out.

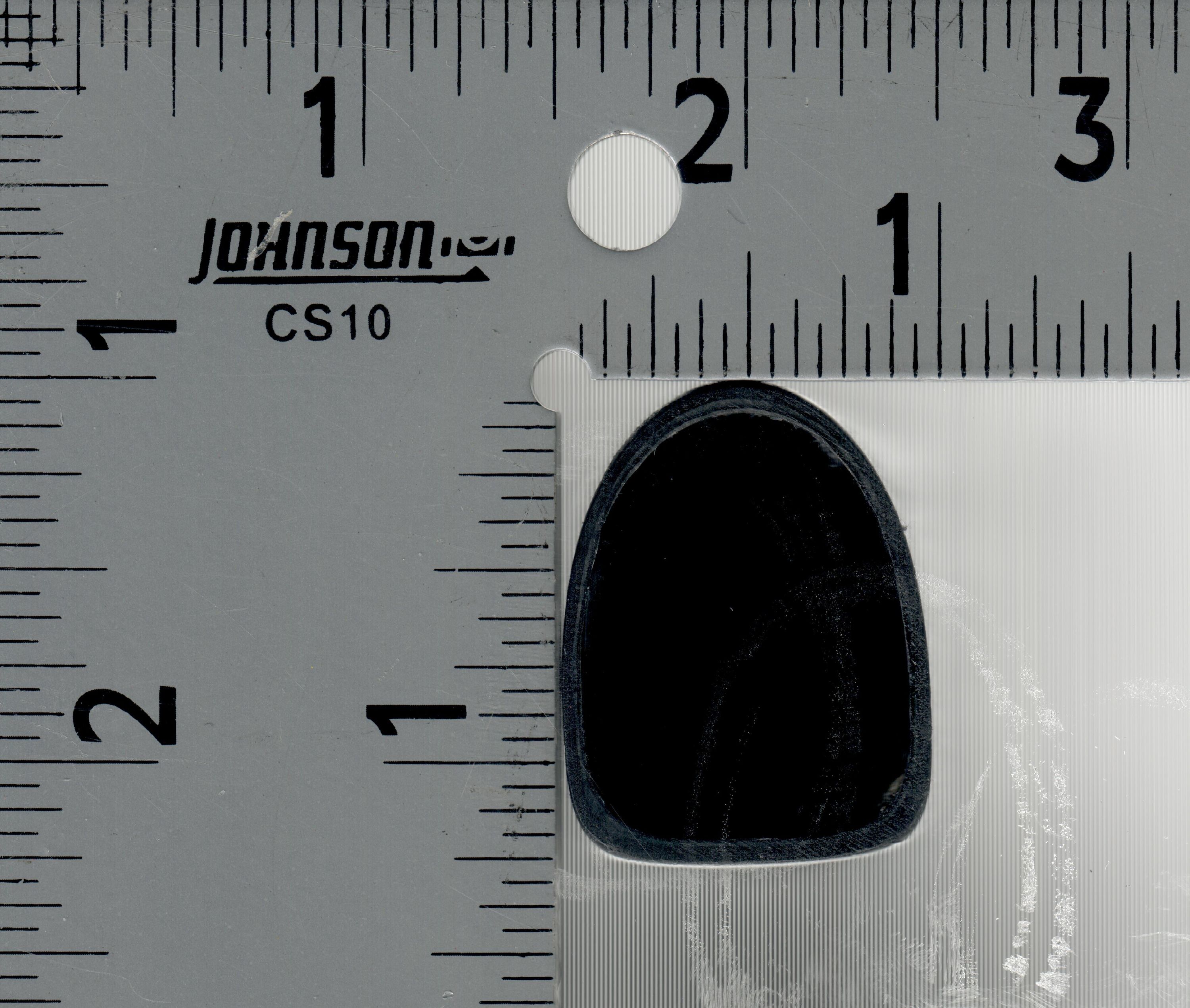
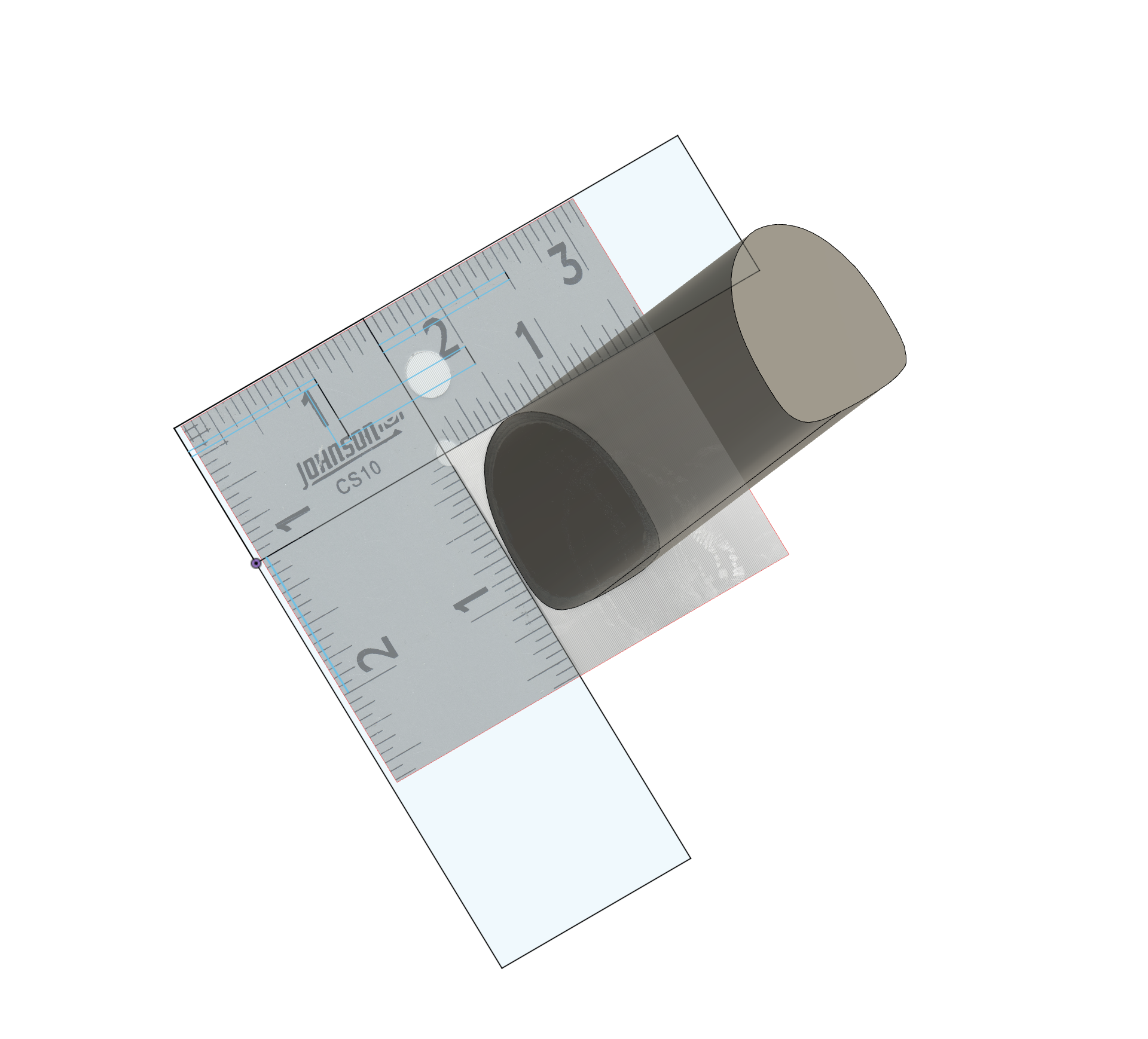
By scanning it besides something with visible measurement, in this case a ruler I had in a drawer. It is then easy to align the scan with “known” sizes in Fusion360, which then gives a good start to sketch out the seatpost and extrude into a shape that can be used for modelling. After that was done, I printed a bunch of smaller prototype fittings to iterate my way into something that would fit perfectly. There’s always some give when you are working with tolerances going from a scanner to 3D printed and making small prototypes is the fastest way of adjusting.

After finding a good fit I made an initial full prototype of how this could work, a ‘clamp’ that would mount around the D-shaped seatpost with a straight extension that morphed into a cup that held the garmin insert together with screws from the behind. The clamp would be held in place with an M5 hex head screw which allows me to adjust tension as needed.

I printed some iterations of this one (grey) This one seemed good when I worked on it but after printing it I realized that it actually didn’t solve the problem. Since the bar is straight, it can’t get past the saddle bag which extends further down. I would have to curve my way around the saddle bag to solve for it. I redesigned it with the learnings from the printed prototypes and made a pretty ugly banana curve. I feel some cringe over the shape but it is also something that’s very functional so I have to just give up on this and accept the banana.
Once I got something that felt “decent” I did some final iterations on the clamp and the cup around the insert and printed a higher quality print. Unlike all the other Specialized models I’ve seen online, I’m publishing this one for free with the Fusion360 file on Printables. Hopefully this helps whoever is reading this in the future to avoid having to trace out the seatpost shape themselves.

August 20, 2024
Andrew Weatherall - Slow Electric Vol. 1 (Massive Mellow Mix)
Just before the COVID pandemic truly hit the world, Andrew Weatherall passed away at the age of 56 years. There is little value of rehashing the importance of his contributions to modern electronic music but to me personally he’s an icon of taste. I’m fascinated by Weatherall’s path in life, where he intentionally forfeited fame and glory (as a potential superstar DJ) for what he believed was the right path artistically for him. His view on music and broad taste is something I still use as a guiding star personally when exploring new music and the connections between tracks.
Weatherall produced and released a wide variety of mixes (thankfully collected on the ‘Weatherdrive’) ranging from 90s rave & breakbeat, onto the minimal techno era of the 2000s with Hypercity all the way to the throwback deep disco of the 2010s but one mix stands apart as different from most released work. “Slow Electric Vol.1” is a mix of mostly slower moving electronic music and for me this is one of the best expressions of Weatheralls broad and eclectic taste in music, many of the tracks on this mix are so obscure that they never even saw a digital release, let alone a streaming release. The mix “Slow Electric Vol.1” is also commonly called “Massive Mellow Mix” and was chronicled about
by Kirk Degiorgio for ResidentAdvisor.
Kirk gets some facts wrong in the article but the thing he’s absolutely spot on about is the debate about the tracks which adds to the mysticism around this mix. Noone seems to have a good handle on when it was made or what tracks were on it. On top of that, the only available ripped version is a cassette recording that’s been spliced together at various points to mask over recording errors, coupled with aggressive audio compression and generational tape loss.
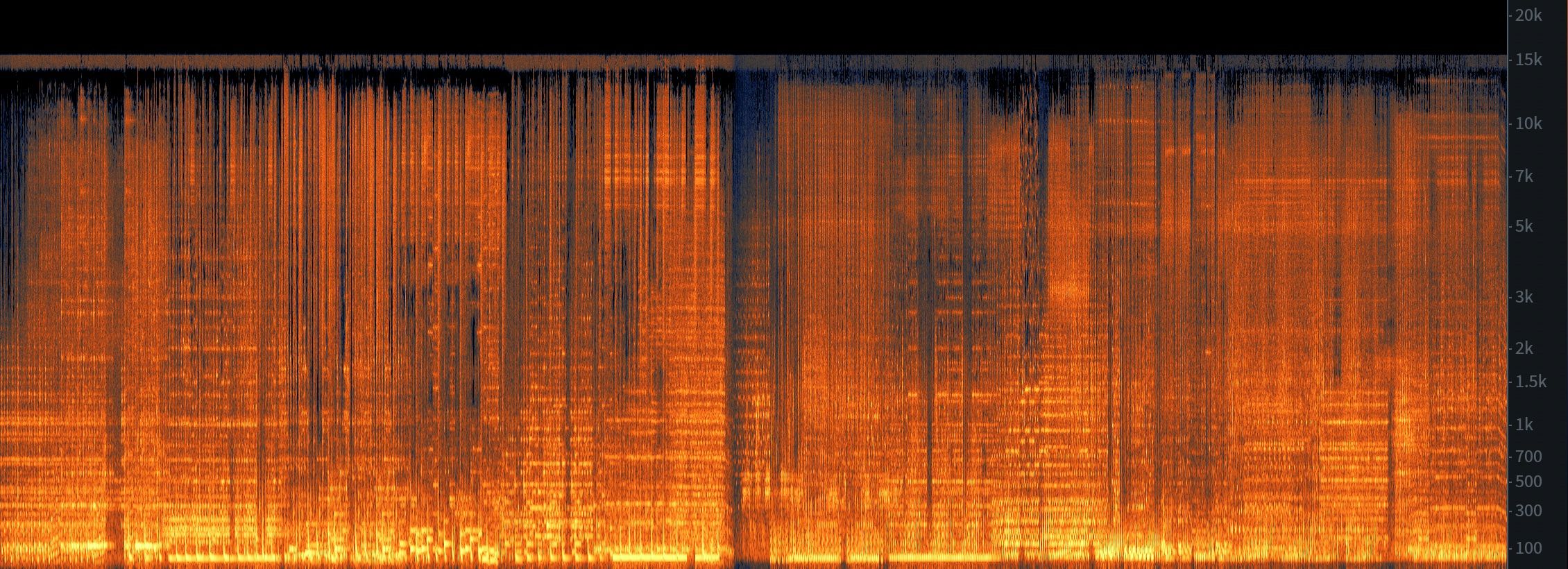
If you listen to the mix from YouTube you can clearly hear the degraded quality but spectrals also shows the 15KHz cutoff that is common with cassettes with the clear “hiss” being visible in the upper range of the spectrum. Even though tape can have it’s charm, the ambient nature of these tracks really suffer from the lossy nature of tape and takes away from the music.
Who ripped this tape? Where did the person acquire the tape? What tracks were used in the mix? How did it end up on the internet? None of these questions seemed to have answers.
So what do we do about it?
This was one of these projects that I intentionally kept deferring, hoping that eventually my mind would lose interest as a way to pressure test if I really cared about working on this. A year passed and this topic continiously kept flaring up in my mind, gently pushing me to spend time on this. I eventually had to accept that I cared about this and that it was worth me diving in. Knowing this, how do we go about answering all these questions? There is no way to access the source mix (Weatherall likely taped it directly from the mixer when recording it), the cassettes available for sale are of equally low quality and the recordings I’ve found all suck. It felt like a roadblock at the time but zooming out I saw another path to answering the questions.
What if we recreated the mix? As in we found the exact source tracks that Weatherall used, aligned it all to the cassette RIP and matched the transitions. If this mix was made later, this would be much harder as DJ mixers started incorporating looping and on-board effects but Weatherall likely spun this one on vinyl on an old 2 channel Vestax mixer with a 3 band EQ per channel, replicating this would not be hard! It solves the problem of “what tracks were used” as only the right one will fit the source material and it also solves the quality issue as we can source the tracks from the highest quality source possible.
The first step was sourcing all the tracks. It took a long time to find the tracks, as it was confusing what tracks were actually used. I was able to source some of the tracks digitally, as some of the artists have released these as part of compilations or anthologies. Some of the tracks however just never seem to have ever made it online, which was the case for a couple of tracks where the artist just seems to have made one album and never followed it by anything. Since I was set on actually recreating this mix, I had to source the vinyls from Discogs and rip them myself. One of them even came in the original plastic (Keyprocessor), for an artist that likely never sold much in the first place. I realize that the record exploring culture was different in the 90s and Weatherall likely sourcing these tracks from friends / shops but it is also sad that the only real discovery of this artist is through the fact that Weatherall at some point stumbled upon it and had the taste to include
it on his mix.

With that said and done, I laid out the version from YouTube into Ableton and started piecing it together. Ableton allows you to “Warp” tracks, as in adjust the tempo without affecting the pitch of the tracks. Contrary to most other Ableton users, this is actually not what we want. If we used Ableton’s global tempo and aligned the tracks as a modern DJ would, the mix would not be a pure recreation but rather just an imitation. You would lose the shifts in pitch that comes from vinyl mixing and the mix. Luckily we are able to use the “Re-Pitch” mode that instead of locking the pitch and adjusting the tempo by algorithmic modification we just speed up/slow down the track, exactly how a vinyl behaves when you tempo match to another deck. Hence when dragging these warp markers, we are adjusting the speed of which the track is playing between each marker.
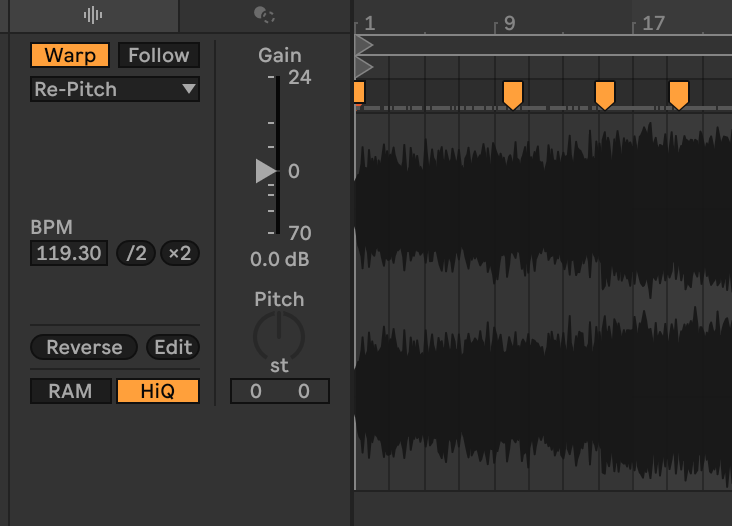
Once I had laid out all tracks it was more obvious where the source taped had been spliced, as the rough alignment started gapping in certain places. Relistening to those specific spots one could easily hear where the person editing the tape had spliced it to fit the tempo of the track, likely cutting a bit more than what was lost to mask it better.
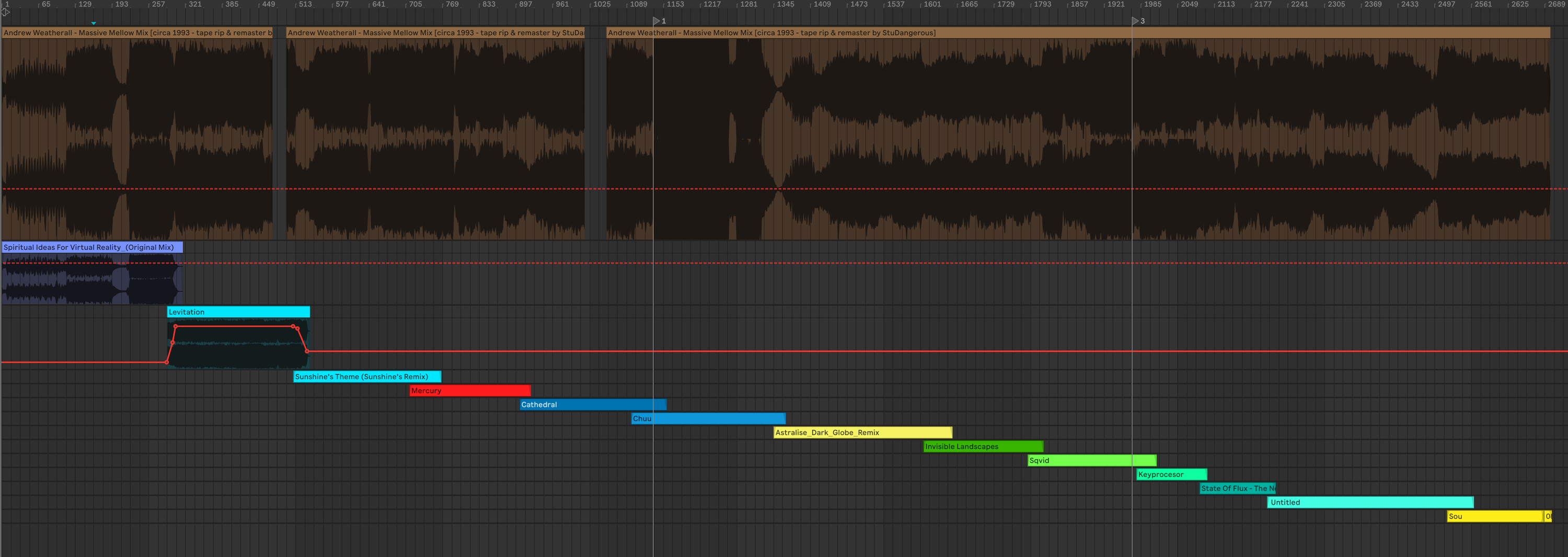
Lastly I had to align the mixes and tempo with what Weatherall mixed, something that wasn’t hard but time consuming. I really wanted to include the “feeling” of the mix, as in to capture the creative decisions and small mistakes that were in the source which meant basically tracking second by second to the source mix and aligning the warp markers. The fun part about this is you can really see where Weatherall was holding his finger on the spindle to slightly slow down the platter as the tempo lightly decreases in a non-linear fashion as the tempo dial on the vinyl decks would do it.
Result
Pressing “Export” in Ableton felt like closing a door to an obsession. After over 3 years of collecting, searching and thinking about this mix, being able to hear this in full quality tracking almost exactly to the source material feels great. Was this worth the effort? Unlikely for anyone else but me. Am I glad I did this? Absolutely.
When was this mix recorded?
Contrary to that the previous uploaded video being dated at 1993, I am almost certain that this mix was recorded in May/June of 1994. The reason for this is that many of the tracks on the mix were actually released in 1994 and not 1993. Since many of the tracks are from early Q2 in 1994, I’m guessing that these are fresh tracks that Weatherall included in the mix. There is also the Reddit user Donkeyshite who mentions being in the band “State of Flux” and their tracks being made and released early 1994, not 1993.
What is the actual tracklist?
- 00:00:00 Hole In One - Spiritual Ideas For Virtual Reality
- 00:09:37 The Primitive Painter - Levitation Klang Elektronik - KLANG 1
- 00:16:55 Dubtribe Sound System - Sunshine’s Theme (Sunshine’s Remix) Organico - ORG 004
- 00:23:40 State Of Flux - Mercury Finiflex - FF1009
- 00:30:03 The Primitive Painter - Cathedral Klang Elektronik - KLANG 1
- 00:36:34 Ebi - Chuu Space Teddy - ST 007
- 00:44:48 Some Other People - Astralise (Dark Globe Remix) Infinite Mass - MASS 018 T
- 00:53:30 The Primitive Painter - Invisible Landscapes Klang Elektronik - KLANG 1
- 00:59:30 Sqvid - Emprisoning Sound On A Piece Of Wax Apollo - APOLLO 16
- 01:05:55 The Keyprocessor - Feary Tales Eevo Lute Muzique - EEVO 008
- 01:09:30 State Of Flux - The News Bold! Stars - BR 2009-1
- 01:13:29 Ian Pooley And Alec Empire - Untitled (Pulse Code E.P. Side A) Mille Plateaux - MP 3
- 01:24:02 Ebi - Sou Space Teddy - ST 007
Story was supposed to end here
In the midst of all the world chaos and polarization it’s easy to forget how cool the Internet used to be. Random strangers would help each other for seemingly no gain and people would excited about building something together. 6 months after I upload this mix to my blog and to youtube, the best part about the internet shimmered once again. I woke up at 4AM for some random reason in February. Unable to fall asleep I checked my phone and saw I had gotten an email titled “Slow Electric 1 - Andrew Weatherall” from a person named Stu.
Just thought I’d reach out based on your obsession with this mix. I’ve been obsessed with it for 30 years and in fact I was the one who ripped it from tape and that rip is the one that circulates on the internet. I did the shitty remastering in audacity with a few pirated plugins from an Akai Walkman to a pc via line in in a flat in Istanbul in late 90s, and spliced it to try and remove the parts accidentally recorded over and fix a very badly hammered TDK cassette that was a copy of a copy of a copy… Myself and a few friends also finally managed to pull the tracklist together during the covid lockdown with the help of a few internet forums and musicheads we reached out to.
The person who ripped the casette and uploaded it emailed me out of the blue? Going back to sleep now was not an option, I had to know, so I got out of bed at 4AM to much dismay from my family. The email reminded me about how I first acquired this mix from. Back in the days I used a site called The Mixing Bowl, a website where users posts mixes that they recorded or acquired, often from BBC (the essential mix). Searching for the mix shows the same file I acquired many years ago uploaded by ‘studangerous’ … Is that the same Stu who emailed me? Going further I decided to check the ID3 metadata of the file and what do you know
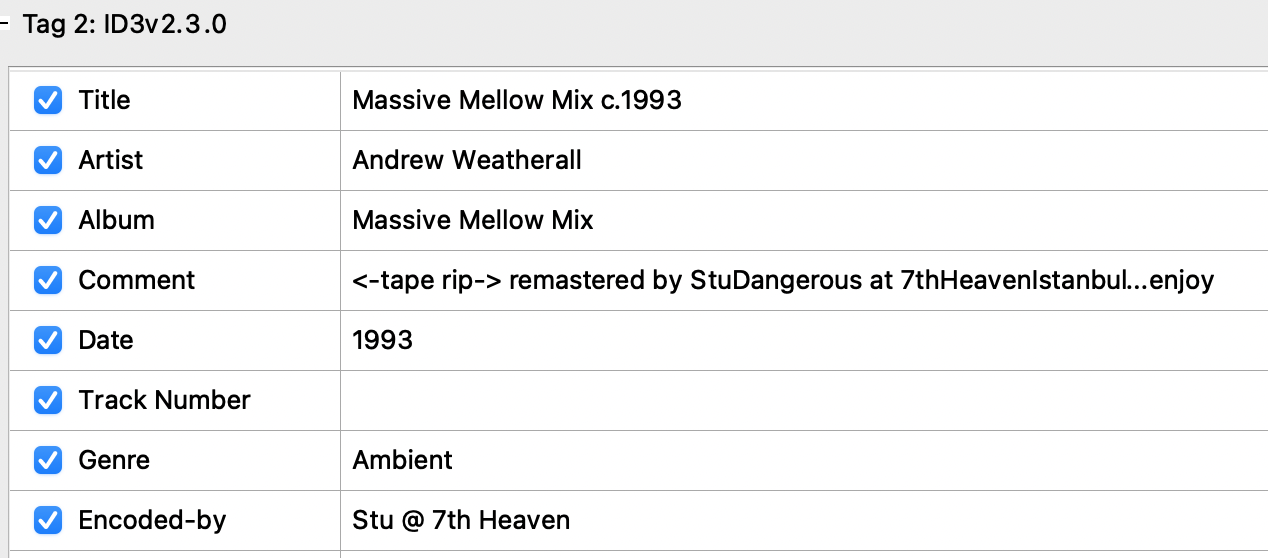
IT WAS THERE ALL ALONG. I never thought of checking the MP3 metadata to find out more about the mix and here I’ve been scouring thorugh youtube comments and manually identifying songs to figure out what tracks was used and what specific vinyl they were released on. I felt both ecstatic and dumb at the same time. In haste I send a bunch of questions back to Stu about how it came to be that he ended up with a casette of this mix and specifically poking around what date this mix would havd been recorded, as I had some evidence pointing to it being 1994 rather than 1993. Stu responds:
First off, thank you for the remake. That’s put a few smiles on afew people’s faces today, mine included. You’ve triggered me re-entering the slow electric rabbit hole and I messaged a few friends who were involved. So to fill in the gaps: my friend Oliver Philips was at Newcastle University bitd and was a huge Sabresonic fan, regularly attending the Sabresonic nights at Happy Jax by London Bridge between 1993-94. AW played Newcastle University at a Sabresonic night on Thursday 12th May 1994. Ollie was racking his brains for the details when I messaged him this morning and he went and trawled through the Uni archives to nail down the date: page 14 of the Uni rag from the archive here
 The gig posting for SABRESONIC in May of 1994
The gig posting for SABRESONIC in May of 1994
At that night Ollie bought two mix tapes, one of which was Slow Electric 1. The other was a much harder mix. Ollie’s now on a quest to dig the old tapes out :)
So a large group of our Friends from that time were from Newcastle, myself and the rest were at Birmingham University. A lot of us came from roots at school: Birkenhead School on the Wirral. We were all involved in the newly emerging UK dance music scene and clubbing, and ran some nights in both locations - Bliss at Birmingham Uni being the one I DJd a lot at.
The glue linking us all together was a mutual friend of all of ours called Mike Ingram, who sadly passed a few years ago, but loved his music and partying and even made a fortune selling a business in the early 2000s. It was his copy of Ollie’s mix tape that I copied.
I moved to Istanbul in 1998 to follow my heart and married a Turkish girl. Around 1999 I made the effort to rip some of my own taped live mixes and a few classics from back in the day from my Akai Walkman via phono line in to my old DX pc. Slow Electric was one of them as it was a mix tape that got hammered by myself and pretty much all of my friends bitd I loved it so much I took to editing it on Audacity with a bunch of pirated plugins from limewire. That took me a couple of weeks to get where I wanted it but I’m no sound technician so it was done on poor equipment with no real idea of remastering, which is why it sounds so bad. I burned a bunch of cds, labelled them up as massive mellow mix as the tape was just labelled as Andrew Weatherall mix and posted them to all of my mates back in the uk.
Many years later I posted the mix to themixingbowl.com torrent site and later hosted on my Mixcloud and soundcloud. The general interest in the mix started to grow from there. I’d been looking for a tracklist for years and when covid hit I suggested to my friends that they get on jqbx and while spinning tunes and chatting with each other the hunt for the slow electric tracklist started. It took a good few months. Another old friend from Birkenhead School, Richie Bell, who also used to DJ with us in Birmingham was instrumental in helping source additional expertise from Facebook groups. He went on to do a live mix remake with the tracks he had and dropped a few others in the gaps left by those he didn’t, which is on his Mixcloud. We slowly built up the track list and eventually cracked it.
And thanks where the story that you know starts I suppose, as the interest grew across the internet from there, accelerating with AWs unfortunate passing and the subsequent launch of the Weatherdrive hosting all his mixes.
Talk about being blown away, this wild sequence of events led to this tape being archived and preserved for us to enjoy years later. Had all of that unfolded and Stu not uploaded it, I would have never gotten obsessed with it and spent this entire effort. We now know so much more, the mix was most definitely made in 1994, the ripped tape was a second generation copy and the best possible version have probably deteriorated over time.
Getting these questions answered satisified my curiosity but what I hadn’t expected was the joy I feel over re-igniting the passion in the people that went out of their way to share this in the first place. It’s the sole validation I wanted for making the effort, that someone, somwhere, would care about this as much as I do.