
MAY CONTAIN HACKERS 2022
MCH is a huge hacker camp in the Netherlands that runs every 4 years (with some timeline adjustments due to COVID). I attended the previous version in 2017 and decided to bring more than just myself this time around. As a continuation of the experimentation with YouTube I made this behemoth of a video about my experience going down to MCH, enjoy!
How was this made?
I got a few questions from people that watched what went into creating it so thought that I would spend some time on explaining it. I started with the rough thinking around what I wanted to capture before even flying to Sweden. Wrote down a number of scenes that I hoped to capture from what I imagined would happen and ranked them in order of importance. Given, almost none of these scenes actually occurred in real life but the work of ideating allowed me to select the right gear to film with. What the exercise outlined was:
- I wanted to capture the experience from “my perspective” rather than a documentary style third person perspective.
- Likely to shoot everything handheld.
- Highly likely that I would be drunk most of the time so there was no time for cinematography or anything of the sort.
- Audio really matters here, I wanted to avoid using visual explanations.
- A lot of the material would be shot in the dark.
Reality here is that I wanted something that would do great on full automatic where I could push the material in post. I had no idea what style would fit so capturing as much as possible seemed like the best path forward. How does one go about doing this? Cameras today allow you to film in formats closer to RAW which helps unlock this functionality.
What is RAW?
Back when digital cameras started becoming popular, most cameras shot in either JPEG or TIFF. Both of these formats are “consumption” formats which require the camera to essentially bake the image from the sensor down to something that could be viewed. Photographers coming from analog film quickly realized the freedom they had in manipulating the negatives to adjust for color and exposure was much more limited with digital since the camera had taken those decisions at time of exposure. To solve for this, manufacturers developed a variety of formats, commonly referred to as RAW images. “RAW” essentially means packaging data from a camera sensor into the file without the decisions made.

So instead of saving a compressed file, the camera spits out the data from the sensor to the memory card without any image processing applied to the file. Since the sensor is made up of individual red, green and blue sensors that capture light it means that it saves the image “bayered”. Tones and colors are also not processed by the camera, meaning that what should constitute “blue” in the picture is left out of the decision making. This is saved at the native bit depth of the camera, meaning there is more information available for every pixel in the image to work later. So if you underexposed a tree, there might be enough information in the blacks to pull that. Above an image processed by lightroom, let’s look at the RAW representation of this image.


You can see that the camera perceives the world very differently to what the final product looks like and in a normal case, the camera will do the work of what Lightroom did above in camera. However if you look at the mosaiced representation, you can also see how much additional data there is in the image. Parts of the image that are dark are in this representation full of additional data which allows us to extract detail from areas that otherwise would lack the depth of data. This magical ability stems from the fact that we have a higher bit depth, a “flat” color profile and the bayer data to infer data about the color surrounding the pixel we are trying to demosaic into a normal image pixel.
Bit depth here is probably the most important part of the puzzle. The image was shot with a Sony A7 IV which shoots images at 14 bits per pixel. 14 bits per pixel might seem awfully a lot considering that normal computer screens only display 8 bits per pixel. In short, 8 bits per pixel means 2 ^ 8 = 256, 256 different levels per color for a total of 256 ^ 3 = 16 777 216 16 million different representable colors. 16 million colors sounds like a lot, why do we need more than this to work with images? If you think about it, these colors are often not evenly distributed. Our eyes do not perceive brightness linearly, rather it’s much more perceptive to luminance changes in “darker” areas compared to light areas. 1 On top of that, there just isn’t enough “difference” if you scale up the data in the lower parts of the bands to create a good image. To illustrate this I’ve created an
image where the top part is an 8 bit image with colors going between 0 -> 16. The bottom half expands the luminance so 0 maps to 0, 8 maps to 128 and 16 maps to 255.

What you can see is that we get what’s known as color banding, perceivable differences between the colors as a result of insufficient detail when projecting the bits out to adjust exposure. So what if we had more bits to work with? 14 bits per pixel 2 ^ 14 = 16 384 colors per pixel -> 16384 bits ^ 3 colors = 4,398,046,500,000 gives us 4,398 trillion colors to work with. So if we use the earlier example where we had 2 ^ 4 = 16 ^ 3 = 4096 we suddenly have closer to 1024 colors per pixel, meaning 1024 ^ 3 = 1073741824 closer to 1 billion different shades of color within the same color band.

This allows us to extract detail in images that would be impossible to retain, both from a color accuracy standpoint and detail standpoint as is obvious above. I used the same image posted above, exported it as TIFF with 8 bits per pixel and applied the same adjustment to both of these which shows you how much detail higher bit depth preserves.
In standard camera industry fashion, no one managed to actually decide on a “standard” format for RAW meaning that almost every manufacturer is using their own format for their cameras. Canon uses CRW (Canon Raw), Nikon runs NEF (Nikon Electronics Format), Sony has ARW etc. Adobe tried to define a standard with DNG which of course went the way of the classic XKCD on standards. Reality is that the “photo management” software (Lightroom, Capture One, Darktable) ended up solving for these differences by unifying the RAW processing with their own image lookup engine. Meaning that at the end of the day, the tools normalize the differences between cameras into an interface that allows the photographer to work with the images the same way regardless of camera.
What about video?
Ok so if you thought this was bad, wait until we enter the realm of video. Since a single RAW image at 4K resolution comes in at around 7-15 MB depending on format, that means that a single second of video would take up to 450 MB. Considering the size of portable storage around the time when RAW photography started becoming popular, storing this from a video camera would be unfeasible. Luckily we have a lot of already developed video compression algorithms using both spatial and temporal compression. I won’t go into the details of video compression but it’s fair to say that every single space-reducing option is exploited, including decreasing bit depth and chroma subsampling.
Contrary to the still image cameras mentioned earlier, most “cinema” cameras are out of reach to normal consumers where this technology pioneered. Cinema cameras are prohibitively expensive with the ARRI Alexa costing more than $100k when coupled with lenses and required accessories. Companies like RED launched REDCODE and ARRI launched ARRIRAW for their ALEXA line of cameras. This meant that the early RAW formats for video ended up being closer to digital intermediates where productions could afford buying 30 proprietary memory cards at $1000 a piece. These formats aim to store as much data as possible and are often “lightly” compressed to facilitate faster playback on desktop computers. Most of these codecs are even built to be GPU accelerated for decoding, as the same methods make them easier to encode on silicon.
“Prosumers” looked at this and quickly realized this was out of their budget and kept shooting H.264 in a variety of flavors. DSLR cameras started to get the ability to record video, getting serious when the Canon 5D Mark II became the first EOS camera to shoot video. It quickly became obvious that the image quality from these cameras coupled with a real lens was superior to that of “professional camcorders”. This ended up giving prosumers the ability to shoot “cinematic” looking footage for the first time without renting a real cinema camera and kickstarted a boom of people shooting features, documentaries and music videos on DSLRs.
So here you have two parallel developments, one aiming to simulate film cameras as closely as possible and one becoming the tool of choice for entry filmmakers almost by mistake. There was however a catch, the DSLRs made all the decisions in the video at time of recording, similar to what your phone does today. This worked but severely limited the ability for users to change the look, exposure and feel of the material after it was shot. This was partly due to limited hardware ability but mostly market differentiation. They simply wanted customers to upgrade to their more expensive cameras as Canon sold a “pro” grade version of their DSLRs. On top of this, all these cameras were shooting 8 bit video which even further limited the ability to adjust colors later, similar to what I showed above.
LOG footage
The story could have ended here but luckily a bunch of people started hacking the cameras, getting creative with what you could coerce the camera into. Eventually people managed to convince the 5D Mark II to record raw footage onto the memory card and other cameras started getting similar features. Sony started getting serious with their mirrorless Alpha line of full frame cameras and started loading up on features to take on the Canon/Nikon duopoly on professional photography.
To shorten the story up, vendors eventually settled on a compromise where the camera records using industry standard compression such as H.264 or H.265 but allows the user to pack the data in ways that makes it easier to adjust later. For example, cameras today often allow users to record in 10-bit, which results in a 98% increase in available color resolution. On top of that, cameras also pack video using a logarithmic profile that distributes the luminance in a more effective way. For example, packing more detail into the shadows and ranges where skin tones are prevalent instead of the highlights.

So this is what comes out of the Sony A7 IV when you shoot in SLOG3 (the third version of their logarithmic packing). You can see that it seems more “gray” which is a side effect of how the SLOG3 profile packs the colors into the 10 bit video. What’s interesting here however is that the way the camera packs the colors are now known both by the camera and you, which means you can counteract the way the colors are packed in a consistent way.

While LOG footage doesn’t give you as much freedom as RAW images does in terms of recovery, it’s great at allowing you to define the look of the video footage after it’s shot. The image above showcases three widely different ways of interpreting the footage, allowing creators to retain their style over multiple pieces of footage.
There are exceptions here. My main “studio” camera, the Blackmagic Pocket Cinema Camera 4K is contrary to the name, absolutely terrible to use as a handheld camera. Blackmagic Design is such an enigma as a company, their RAW story is years ahead of the rest of the industry but their cameras still manage to get so many things wrong. If Blackmagic ever produces a handheld camera that isn’t eating batteries for breakfast, has hardware image stabilization, great autofocus and a reasonable LCD screen they will have ended the rest of the industry. Knowing Blackmagic though they likely will keep staying weird.
Shooting it
I’ve amassed a large amount of gear over my 10+ years of working in broadcast and at a certain point the challenge is in what gear to leave behind rather than what gear to bring. The more gear you carry the harder it is to be spontaneous. Since I probably would be hauling everything on my back in addition to my own clothes etc it made sense to pair this down. At the same time, just bringing a GoPro and a stick would limit the amount of flexibility I get. GoPro’s have developed to look almost too good for their size but they are still terrible in low light due to the sensor size.

After considering this for a while I decided to try using the Sony A7 IV (which is our main photography camera these days). It amazes me how far mirrorless cameras have come to where I began in broadcast. Not only does the camera shoot 4K in 10bit with great colors, it only has what’s probably the best autofocus on the market. The autofocus is bang on, all the time, something that really matters when you’re holding the camera in your left hand, drunk, tired, on a field in the Netherlands.
I coupled this with the Sony FE 16-35mm F2.8 GM lens, a wide angle lens that allowed me to easily film myself while holding the camera in my hand. I wish the lens was 18-50mm but lenses in that range often had apertures at 3.5 or 4.5 which was less optimal at night. The reason a lot of the material came out so clear is due to the wider aperture of this lens, allowing the camera to soak in the available light.
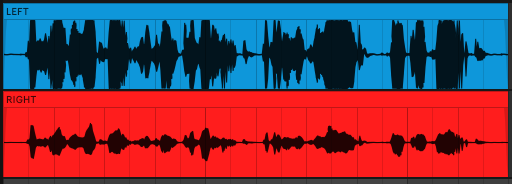
On top of the camera I slapped the RØDE VideoMic NTG which did a decent job of capturing directional audio. Videomics used to be a hassle but this mic turns itself on automatically when the camera starts and likewise shuts down when the camera does, preserving battery. It also records bracketed audio in the microphone, something that basically allowed this video to even be made. What does bracketed audio mean?
Similarly to images, audio has a limited amount of range that it uses to represent signals. In the digital world you measure audio in decibel downwards from maximum, meaning that 0 dBFS is the maximum at which point there is no more headroom available to represent the audio. This is what people call “digital clipping” and creates unpleasant distorsion in the audio.
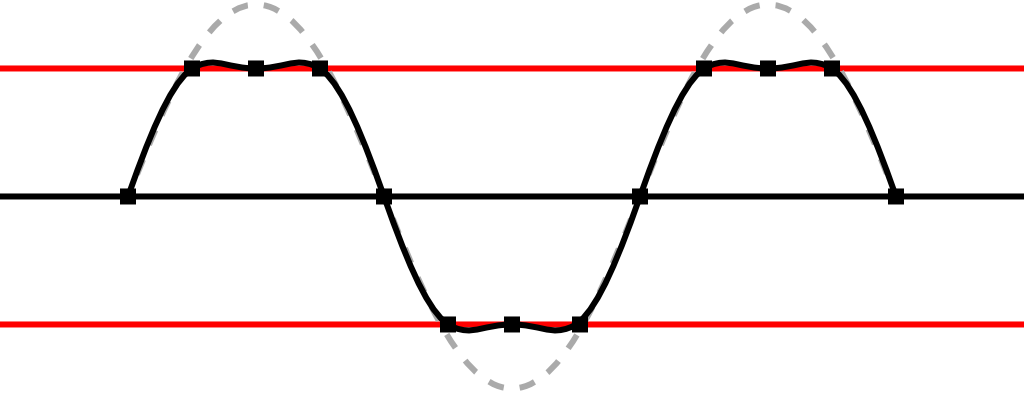
The first clip here represents how the audio should sound like
And this is what happens when a microphone captures audio that’s louder than what the available headroom is configured to
This is really hard to predict when filming. If you set the gain too low, you risk not having enough signal to hear what people are saying and if you set it too loud you’re unable to deal with people speaking loud, music or yelling. Bracketing solves this by recording two different versions of the audio, exploiting the fact that the microphone is mono recording onto a stereo track. Instead of duplicating the first track to the second to fill the stereo audio, the microphone records the left channel at the set gain and the right channel at -20dB. This way there’s always a safe option to mix over to in post production if you blow out the left channel with a safe duplicate of the audio.
Editing
It’s hard to say exactly when Blackmagic’s DaVinci Resolve crossed from being clown software into being actually good. I know trying the editing around version 11 and being severely unimpressed. Contrary to my earlier judgment, Blackmagic’s approach has paid off as they now sit on what I think is the only tool on the market that’s a “one stop shop” for editing -> compositing -> grading. No other tool allows you to simply do all of these things while also costing $0 ($295 if you need the professional codecs). It’s remarkable how good Resolve has become and editing this was a joy, apart from the classic odd bugs that only Blackmagic can manage to produce.
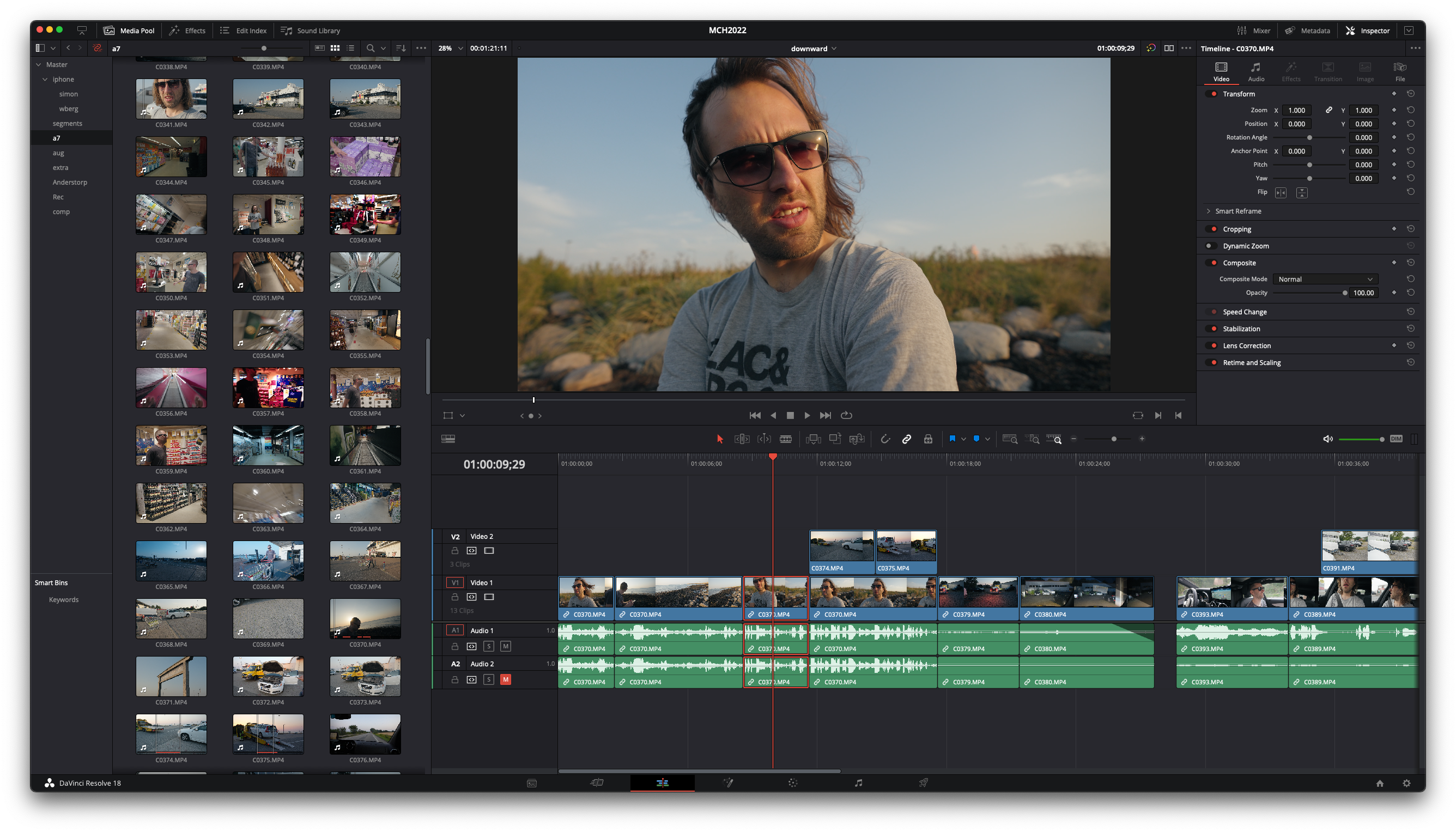
Resolve also allows you to import timelines into timelines, meaning that you can build nested storytelling components in isolation and assemble these later. This is something I always wanted from my time using VEGAS back in 2008 when timelines quickly became insanely complicated and hard to change.

Basically I cut all of the parts as individual segments ad-hoc. One of the mistakes I made when shooting is that I explained too little while on site. There was a lot of understanding of what we were doing in my head that I never articulated on the camera which made it really hard afterwards to come up with good ways of piecing together the story. Editing always starts from the storytelling and I was sitting with more of a collage of videos. To get a feel for how this could fit together, I edited the segments which I knew would work and went from there, eventually adding more voiceovers and new footage to supplement the footage I didn’t have from the event.
Would I do this again? Hard to say. The material is probably more fun to watch if you visited the event. Doing this again probably requires me to re-adjust my own participation in an event like this, focusing more on actually filming than creating the events for the participants. This tension is what kept me from doing a better video this time around so we’ll see. Bornhack did ask me to do a similar one for them so maybe that’s the jam? Time will tell.